The Kontent.ai delivery API enables us to retrieve content from the CMS easily. For content that updates regularly, via the management API or frequent content updates it also provides a way to ensure that the content being retrieved is not stale. It's an easy feature to use so long as you know how and when to use it.
Keeping content up to date is important in any channel. If content updates regularly either via integrations with the CMS or a busy editorial team, we want to make sure that the latest updates are available to our users.
When we're querying Kontent.ai using the Delivery REST API, there is an HTTP header we can use that instructs the API to only return fresh data. It's named X-KC-Wait-For-Loading-New-Content.
When this header is set, the API will wait for new content to be processed before data is returned from the API, ignoring any previously cached data for the same request. If we don't set it, then the delivery API will return a cached response to our query.
Adding the X-KC-Wait-For-Loading-New-Content Header
Depending on which stack we're using, how we add the header can look a little different.
In JavaScript, you can see that the query configuration can be passed in per request:
// Set wait header in JavaScript
const client = KontentDelivery.createDeliveryClient({
projectId: '<PROJECT_ID>',
});
const response = await client.item('my_post')
.queryConfig({ waitForLoadingNewContent: true })
.toPromise();Whereas the following example in .NET sets up the client as always waiting for fresh content:
// Set wait header in dotnet
IDeliveryClient client = DeliveryClientBuilder
.WithOptions(builder => builder
.WithProjectId("<PROJECT_ID>")
.UseProductionApi
.WaitForLoadingNewContent
.Build())
.Build();
IDeliveryItemResponse<Post> response = await client.GetItemAsync<Post>("my_post");Overall, I prefer the JavaScript approach here, as it allows developers to be explicit about when the fresh content is important to our application. With the .NET approach, it feels a little like a sledgehammer and might cause us to think about registering multiple clients to get the best performance for our application.
What are we waiting for?
A key thing to note is that, when the header is set, only the root items of the query are checked for freshness. Any linked items/modular content will not wait for stale content to be flushed.

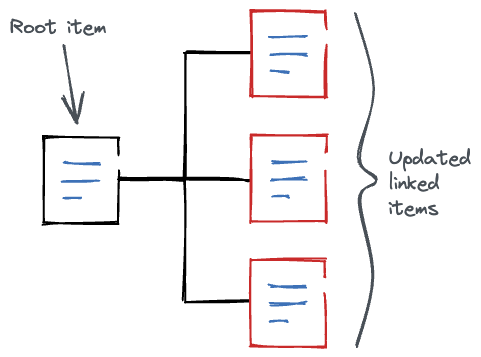
In the above diagram, the root item in the query itself has not changed but the linked items have. When we request the root item and include the linked items, the delivery API will return a cached query response.
In my example, I have a Courses type that has Availability Slots as linked items. A scheduled job keeps my availability slots synchronised with an external service. When these slots are updated, I then create a denormalised view of my data in an Azure Cognitive Search index to allow users to search for courses. But, If I process my data too quickly relying on getting the course and its availability slots in a single query, then I run into problems.
To make sure I get the latest versions of the linked items, I request them at the root level of a query as follows:
// in order to get the latest availability data, we need to request the slots directly
const availabilitySlots = await getClient()
.items()
.queryConfig({ waitForLoadingNewContent: true })
.inFilter(
'system.id',
course.availability.value.map((a: any) => a.system.id),
)
.toPromise()
.then((response) => response.items);This promotes the course availability slots to the root of the query and waits for the updates to finish processing to make sure that the fresh data is returned.